Why Does MySQL Use B+ Trees Instead of Skip Lists for Indexing?
===============================================================
Today I saw a very useful and clear video about the explanation of B+ tree and skip lists in Database, so I want to write a blog to record my understanding.
When we think about MySQL tables, they seem to be simply storing rows of data, similar to a spreadsheet.
Directly traversing these rows of data gives us a performance of O(n), which is quite slow. To accelerate queries, B+ trees are used for indexing, optimizing the query performance to O(log n).
But this raises a question: there are many data structures with log(n) level query performance, such as skip lists used in Redis’s zset, which are also log(n) and even simpler to implement.
So why doesn’t MySQL use skip lists for indexing?
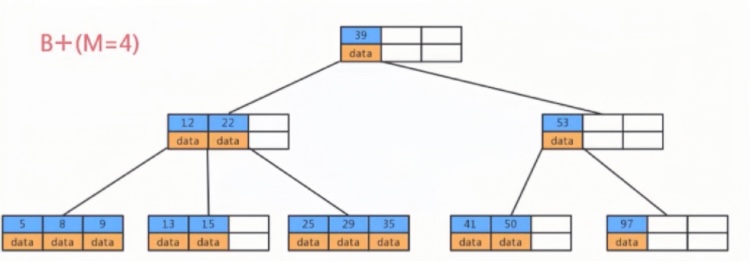
The Structure of B+ Trees
Generally, B+ trees are a multi-level structure composed of multiple pages, each being 16Kb. For primary key indexes, the leaf nodes at the lowest level hold row data, while the internal nodes hold index information (primary key id and page number) to speed up queries.
For instance, if we want to find row data with id=5, we start from the top-level page records. Each record contains a primary key id and a page number (page address). Follow the yellow arrow; to the left, the smallest id is 1, to the right, the smallest id is 7. Therefore, if the data with id=5 exists, it must be on the left side. Following the record’s page address, we arrive at page 6, then determine id=5>4, so it must be on the right side in page 105.
In page 105, although there are multiple rows of data, they are not traversed one by one. The page also has a page directory, which can speed up the query for row data through binary search, hence finding the row data with id=5 and completing the query.